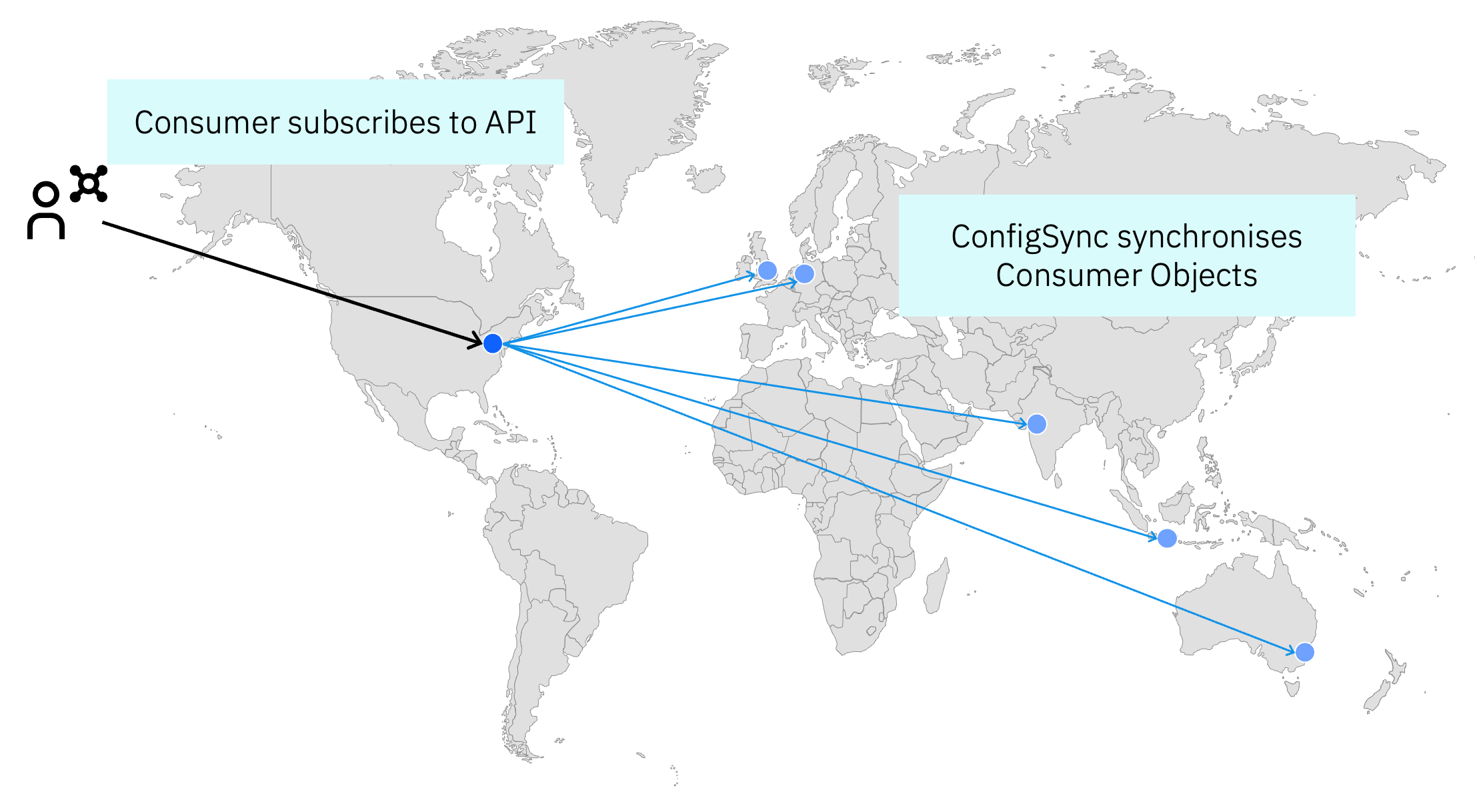
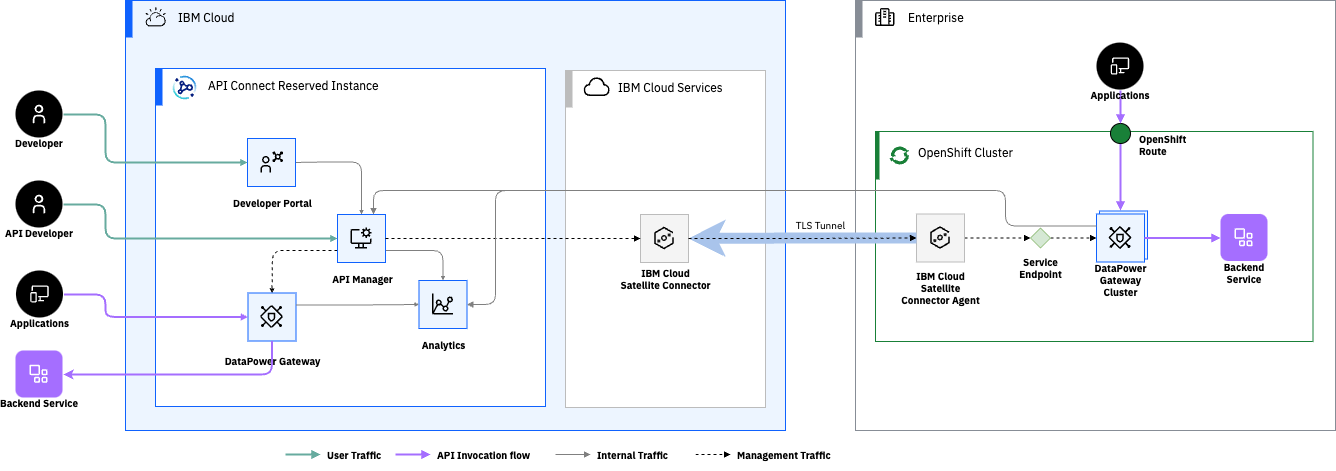
Designing for Multi-Region API Deployments
The requirement to be multi-region usually comes suddenly, an immediate business demand, a compliance deadline, or the aftermath of an incident. When designing API Connect SaaS, the decision was to build each region completely independently. Within a region it's highly available across availability zones, but the regions themselves don't replicate. The reasoning is straightforward: as a shared API management platform serving customers with fundamentally different requirements - data residency, cross-region resilience, or both - independent regions let each customer build the topology that fits their constraints, rather than the platform prescribing one.

What is your requirement anyway?
The first thing to consider when designing a multi-region API deployment is to make sure you are clear on what the fundamental business requirement is that is driving you towards a multi-region strategy. There are a number of routes that lead towards multi-region planning and they will all drive different variations to the design.
- Latency - ensuring your APIs respond quickly from the regions you have consumers calling them
- Resilience - providing a failover for if there are issues in one region.
- Compliance - ensuring data and/or traffic to remain in a particular region
For improved latency across regions - is this required primarily around read APIs or do you need to handle write operations as well? If it is primarily reads, then you may be able to reduce your latency with the use of a CDN with edge caching without the complexity and cost of a full multi-region deployment.
If you're looking for resilience, will your requirements be satisfied with a primary region that normally will handle everything and a secondary location that can pick things up if the primary is down or do you need them both to be able to handle traffic in parallel? How long can you cope with a failover between regions taking - seconds or hours? These are the factors that will drive how you go about implementing a multi-region solution.
An API is only as good as its data
Whilst it is relatively easy to replicate API Gateways and application servers between regions - this only gets you so far, as at the end of the day the API depends on a data source. Where does the data for your API reside - what requirements for data storage need to be factored into the overall architecture?
If you have an API that is read-heavy and the data is not time critical you may be able to use replication with eventual consistency saving on the performance hit, cost and complexity of ensuring strong consistency between replicas.
If you have a write heavy API - how will you handle conflicts between writes across regions - will you need to add application or data level locking or would you enforce some form of queuing?
To improve performance across regions the other approach could be to have regional caching to reduce the need to retrieve data from the master source, but this will require careful management of time to live values for cached data so that it remains within an acceptable freshness threshold which will differ between data types.
Auth dependencies are the hidden failure mode
If your identity provider or authorization service is centralised then a regional API failure may be the least of your worries if auth itself is unavailable. API Connect SaaS uses IBMID for it's management plane identity provider, highly available in it's own right, but not part of our regional deployment. Importantly though it's not involved in runtime authentication for customer APIs or their developer portals so any failure doesn't cascade to impact live traffic.
If you can validate JWTs locally without needing to call out to a central service then in most cases you are good, but what happens if you need to revoke a token - do you have a robust system for sharing a revocation list?
How are you handling rate-limiting - is this maintained within the region or do you have a way to track usage across the regions? Within DataPower API Gateway the rate-limiting is maintained through the peering group, requiring a low-latency connection to keep them in-sync. For the DataPower Nano Gateway this can be externalised to your own Valkey or Redis deployment which you could deploy using cross-region replication. Whatever solution your rate limiting is based around, ensure that the period over which the rate is set aligns with the latency in your replication - for example if the replication may sometimes take more than a second you can't use per second rate limiting and would be better to calculate the equivalent over a larger period.
Routing and traffic management
How do you route traffic through your system - starting from the consumer - do you want to expose the regions to them or should they just continue to use a known endpoint and it just works? If you are maintaining a global endpoint you will need some form of global traffic routing - either DNS-based or some form of load-balancing. If you stick with regional endpoints - how are they discovered by the consumer - are they all just servers listed in the OpenAPI specification? Do you provide guidance to the developers building against your API on how to handle retries and failover across regions?
If there are cases where there is state involved, maybe you need some form of session-stickiness to keep the traffic in the region it starts. The techniques you would use here would completely depend on the type of clients you are building for - if this is pure API clients you would need something client IP based, if it's browser based clients, cookies are an option.
If you have global endpoints what controls the routing or failover to a different region - is this purely based on health-check response, latency based or some intelligence based on the inbound IP address and which region is closest to them? For the stateless common components in our API Connect Reserved Instance console we have them available in each region and use broad GeoIP based routing to try and serve inbound traffic from their nearest endpoint with a failover - GeoIP based routing helps to a degree but IP geo-location isn't always accurate.
Failure modes and failover
If there is an issue with one of the regions, how do you detect it and what happens next? Of course if you have to serve traffic within region it may just be a case of waiting it out.
How do you test the failover? Any failover plan is only any use if it works so it is crucial that you have a way to test this. Ideally you would identify a way simulate a failure and trigger the failover - then you can ensure your observability covers this to show what is happening during a failover. Also worth considering when you look at observability for a multi-region solution is whether you define Service Level Objectives by region or across the solution and how you track these, along with the resilience of your monitoring tooling as well.
Actual failures aren't always as cut and dried as the test however - you may find that a region is only partially impacted or continues to run just without any network connectivity. These are key factors to consider when determining the trigger for failover but also for clarifying the state of the system during the failover and what actions will be needed to move back to normal operation after the failover. It may be that you need to treat a region as completely down even when it isn't so as not to end up with split-brain across the regions data - then restore a backup there in order to return to normal afterwards. This was a fundamental part of how we used to deal with replication in Informix - where if there was a network partition we would find multiple nodes continuing to run as primary and we would need to select which node to reset. This was usually the one with a secondary server still attached, but occasionally there would be workload continuing on the standalone primary and nothing happening in the clustered one. The same principle applies here at a higher level: sometimes the safest recovery path is to treat a degraded region as completely lost and restore cleanly rather than trying to reconcile state.
Are there parts of your system that need to be disabled during a regional failure and run in a degraded mode as they add more risk or aren't as crucial to maintain availability on?
Most multi-region requirements aren't as simple as just adding another geographic location - there is a lot more to think through across the different layers of your system - data, auth, routing and how it actually will handle failures. Going back to where we started, the right answer will depend on the requirement you are building for. Latency, resilience and compliance will each take you in different directions as you design so it is key to have clarity up-front rather than trying to do everything and over-engineering a solution. For more on designing with reliability in mind from the start see SRE Mindset in API Architecture or for an example of how this could be done see my post on building a global deployment with API Connect.